mygrad.nnet.activations.relu#
- mygrad.nnet.activations.relu(x: ArrayLike, *, constant: bool | None = None) Tensor[source]#
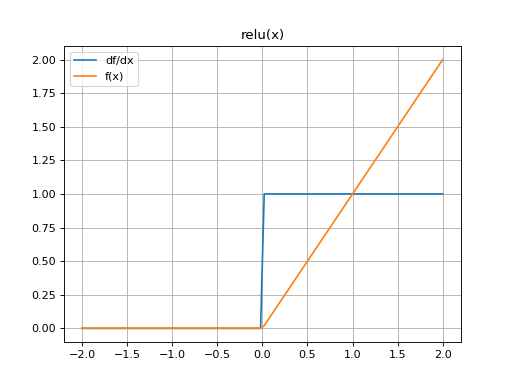
Applies the recitfied linear unit activation function:
f(x) = {x, x > 0 0, x <= 0 }
- Parameters:
- xArrayLike
relu is applied element-wise on
x.- constantOptional[bool]
If
True, the returned tensor is a constant (it does not back-propagate a gradient)
- Returns:
- mygrad.Tensor
Examples
>>> import mygrad as mg >>> from mygrad.nnet import relu >>> x = mg.linspace(-5, 5, 5) >>> x Tensor([-5. , -2.5, 0. , 2.5, 5. ]) >>> relu(x) Tensor([-0. , -0. , 0. , 2.5, 5. ]) >>> relu(x).backward() >>> x.grad # d(relu(x))/dx array([0., 0., 0., 1., 1.])
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}